|
Email / CV / Google Scholar / LinkedIn / Twitter / Github
Jinlu Zhang is a Ph.D. student in CFCS, School of Computer Science, Peking University, supervised by Prof. Yizhou Wang.
|

|
Research |
|
My current research interests include computer vision and machine learning.
I am focusing on Human-centric 3D vision, and Intelligent agent interacting with human in 3D world. |
News |
|
[2025.02]
One paper accepted to CVPR 2025 as Highlight, focusing on 3D human object intraction.
[2024.02]
One paper accepted to CVPR 2024 as Highlight, focusing on 3D human motion generation.
[2023.11]
One paper accepted to TPAMI, a comprehensive survey on 3D human motion generation.
[2023.07]
One paper accepted to ICCV 2023.
|
Preprints |
|
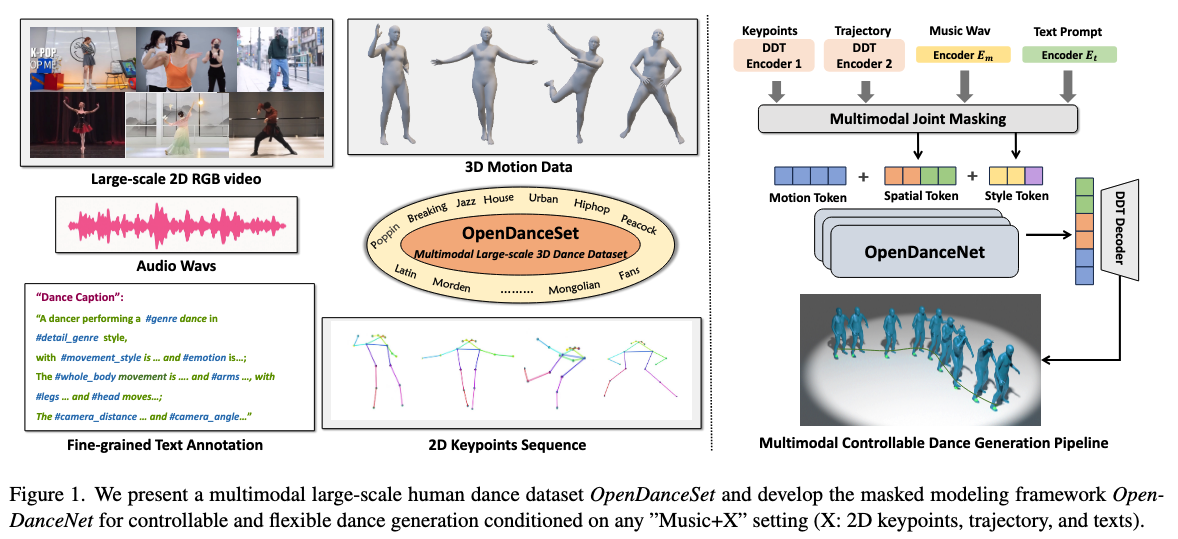
OpenDance: Multimodal Controllable 3D Dance Generation with Large-scale Internet Data
Arxiv, 2025 Paper/ Project pageAbstractIn this paper, we build OpenDanceSet, an extensive human dance dataset comprising over 100 hours across 14 genres and 147 subjects. Each sample has rich annotations to facilitate robust cross-modal learning: 3D motion, paired music, 2D keypoints, trajectories, and expert-annotated text descriptions. Furthermore, we propose OpenDanceNet, a unified masked modeling framework for controllable dance generation, including a disentangled auto-encoder and a multimodal joint-prediction Transformer. OpenDanceNet supports generation conditioned on music and arbitrary combinations of text, keypoints, or trajectories. Comprehensive experiments demonstrate that our work achieves high-fidelity synthesis with strong diversity and realistic physical contacts, while also offering flexible control over spatial and stylistic conditions. |
|
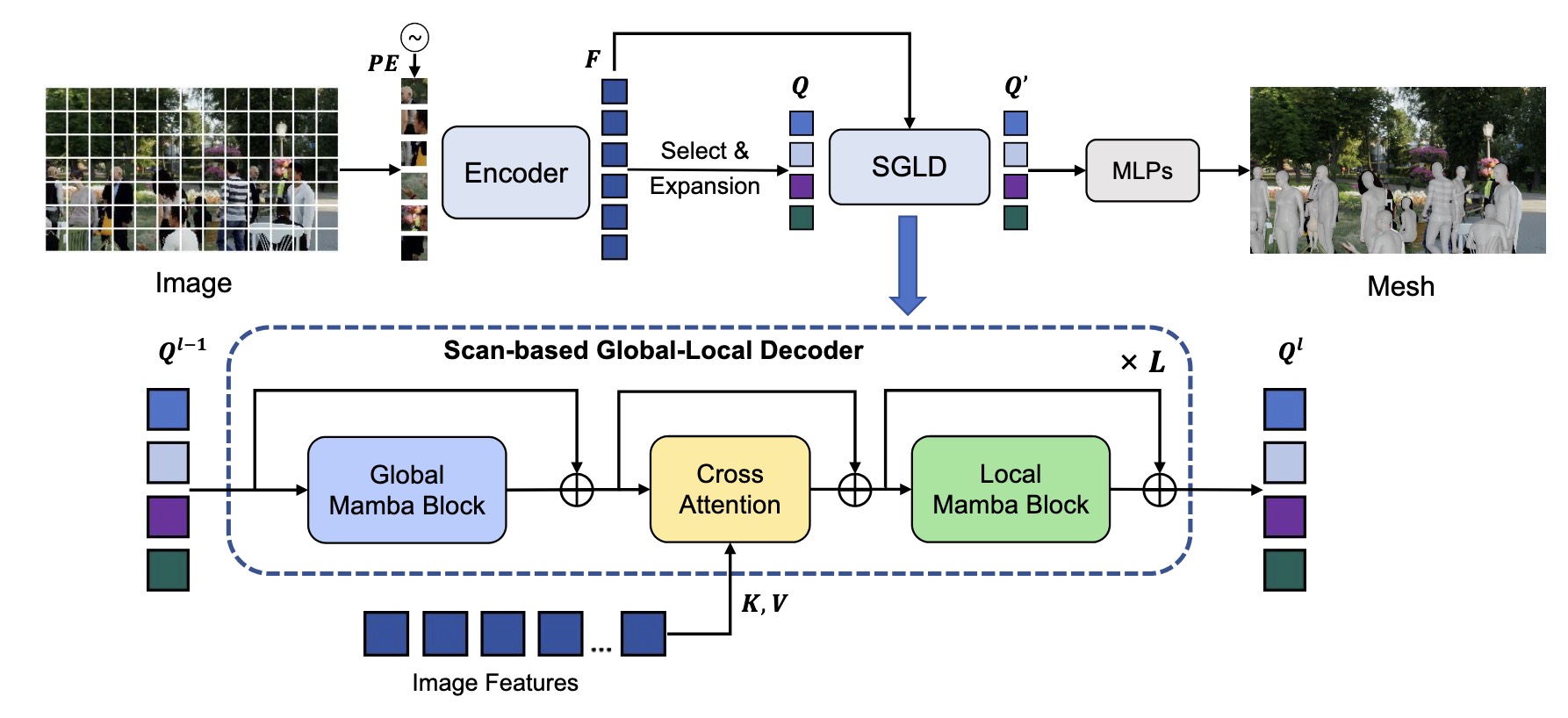
EMO-X: Efficient Multi-Person Pose and Shape Estimation in One-Stage
Arxiv, 2025 PaperAbstractOur EMO-X leverages the superior global modeling capability of Mamba and designs a local bidirectional scan mechanism for skeleton-aware local refinement. Notably, it achieves a significant reduction in computational complexity, requiring 69.8% less inference time compared to state-of-the-art (SOTA) methods, while outperforming most of them in accuracy. |
Publications |
|
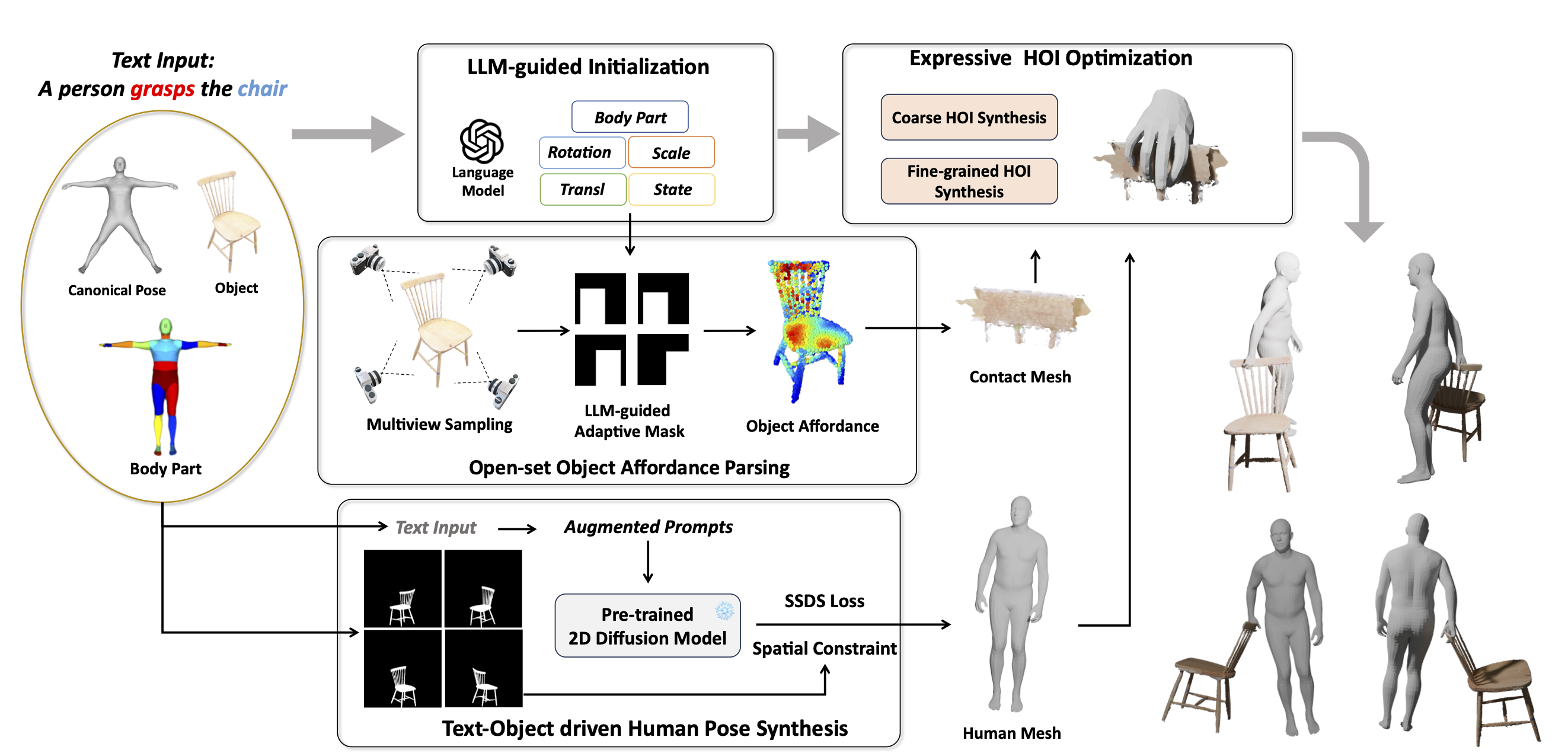
InteractAnything: Zero-shot Human Object Interaction Synthesis via LLM Feedback and Object Affordance Parsing
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 Highlight Project page/ PaperAbstractIn this work, we propose a novel zero-shot 3D HOI generation framework without training on specific datasets, leveraging the knowledge from large-scale pre-trained models. |
|
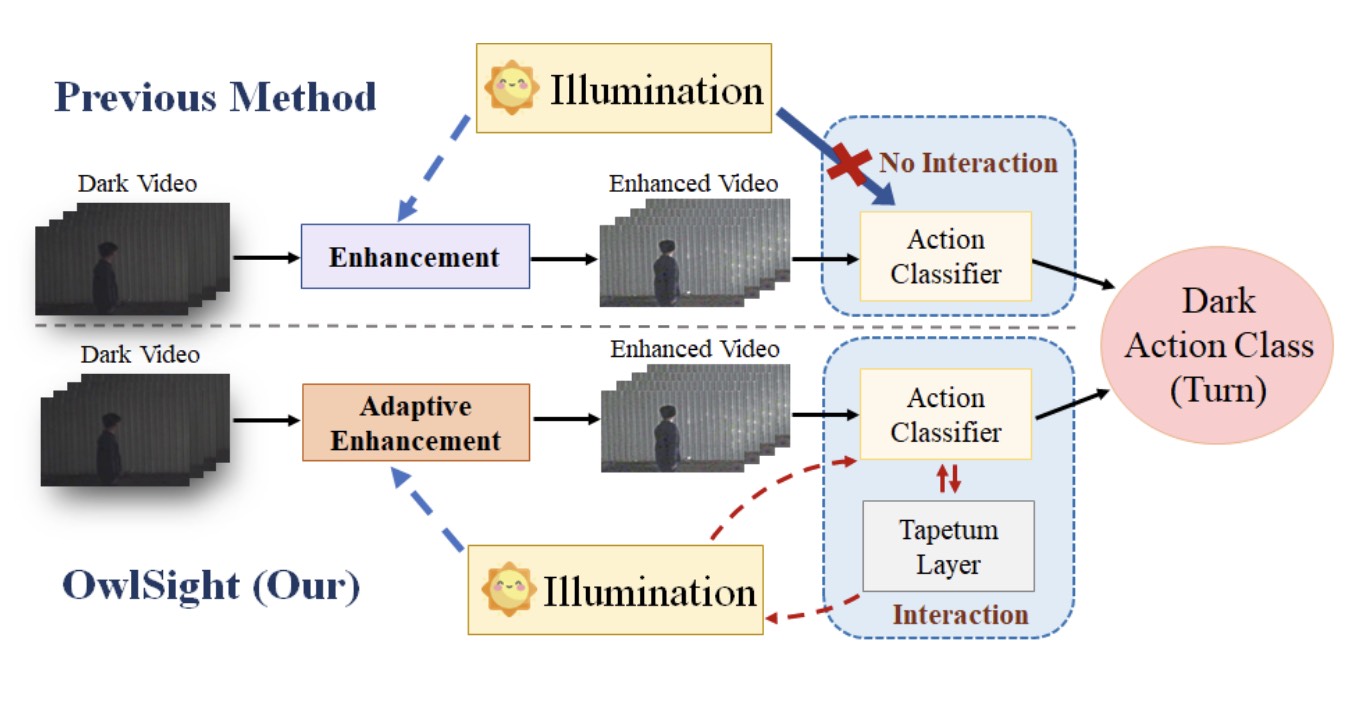
OwlSight: A Robust Illumination Adaptation Framework for Dark Video Human Action Recognition
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025 PaperAbstractWe propose OwlSight, a biomimetic-inspired framework with whole-stage illumination enhancement to interact with action classification for accurate dark video human action recognition. |
|
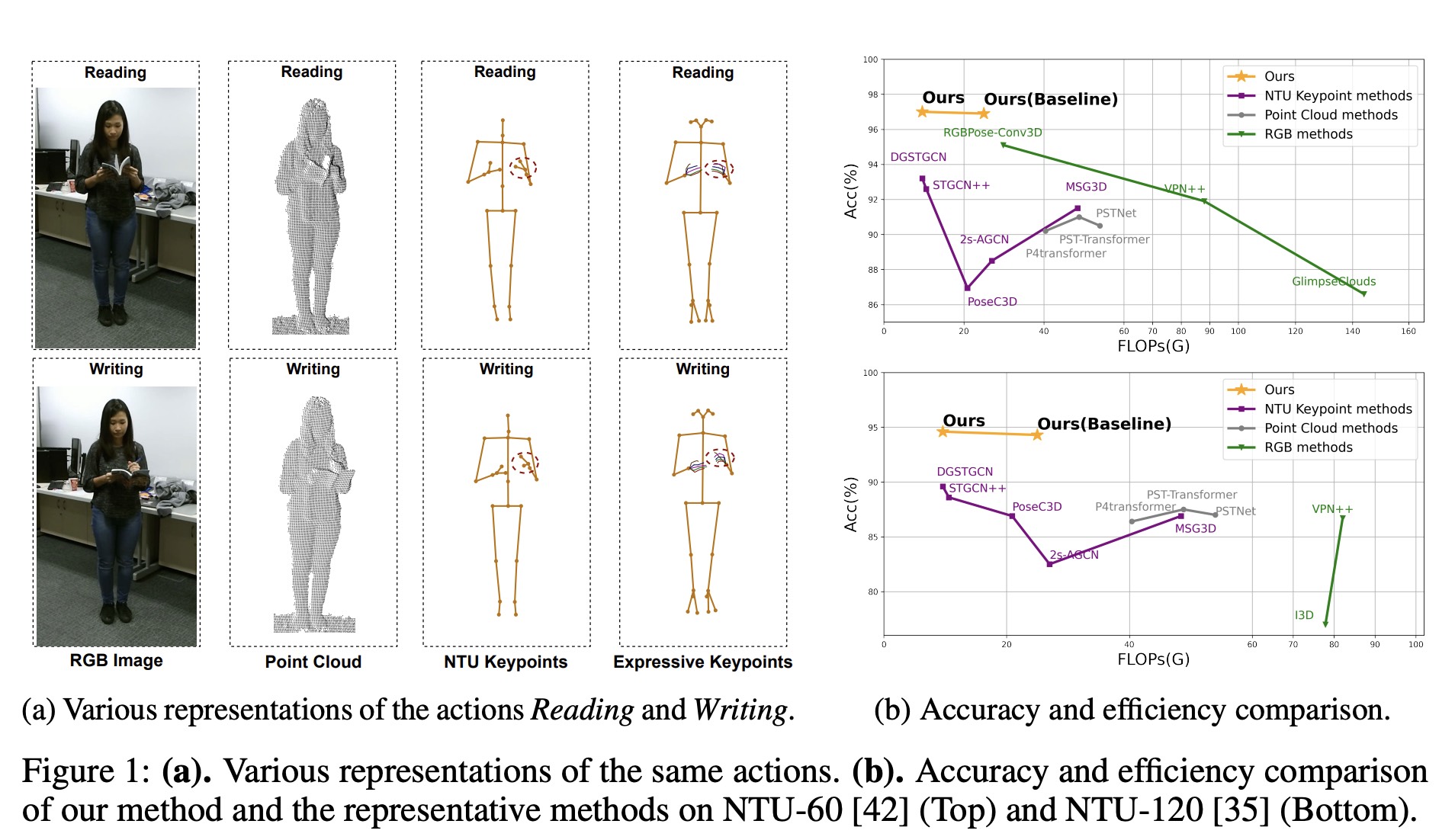
Expressive Keypoints for Skeleton-based Action Recognition via Progressive Skeleton Evolution
IEEE Transactions on Image Processing (TIP), 2025 Paper/ CodeAbstractIn this work, we propose Expressive Keypoints that incorporates hand and foot details to form a fine-grained skeletal representation, to improve the discriminative ability for existing models in discerning intricate human actions. |
|
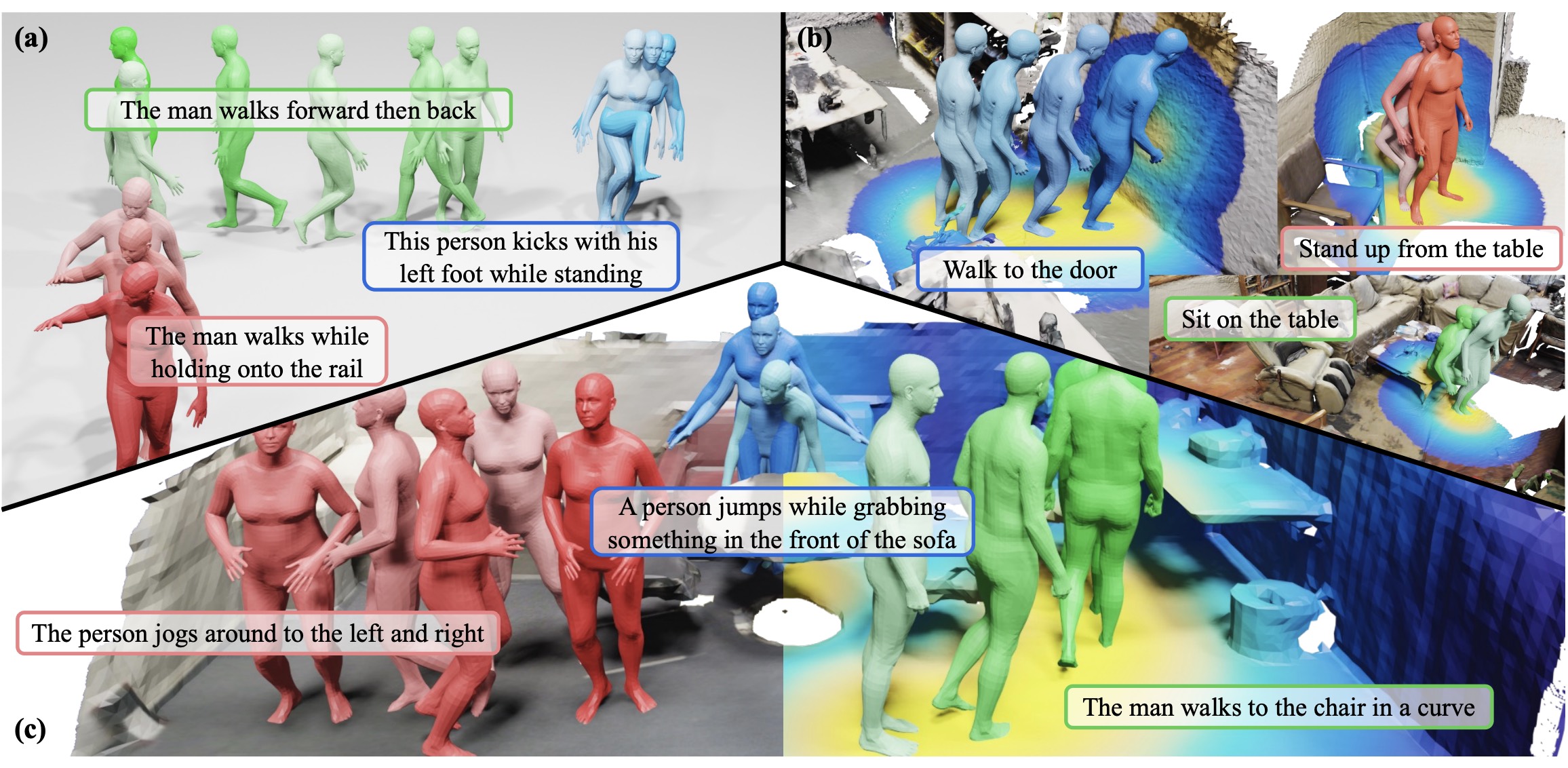
Move as You Say Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 Highlight Project page/ Paper/ CodeAbstractIn this work, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. |
|
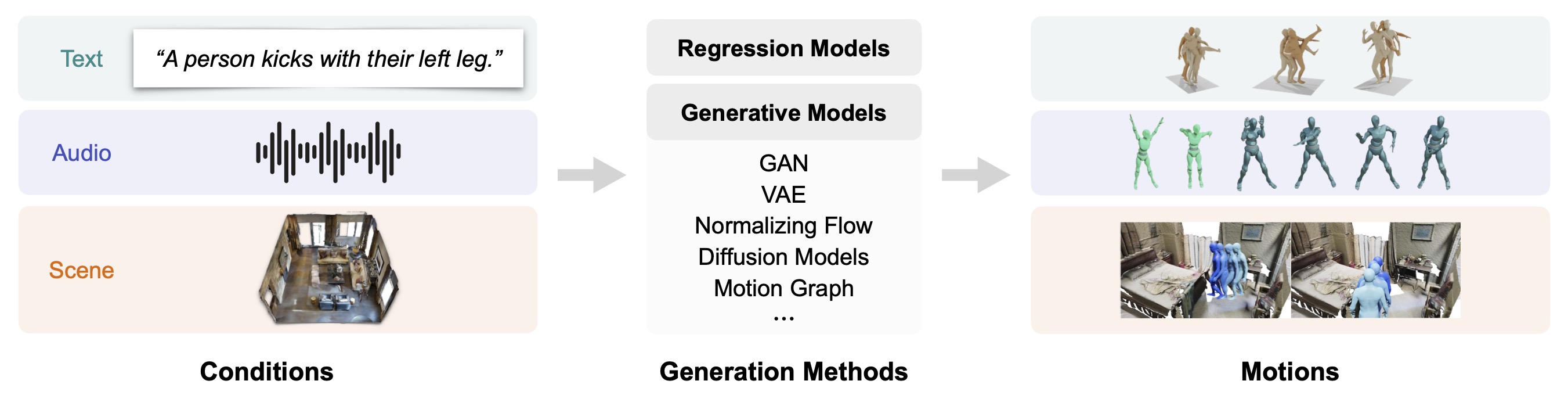
Human Motion Generation: A Survey
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 PaperAbstractA comprehensive survey of recent advances in human motion generation, covering the technical evolution, key challenges, and future directions in this rapidly developing field. |
|
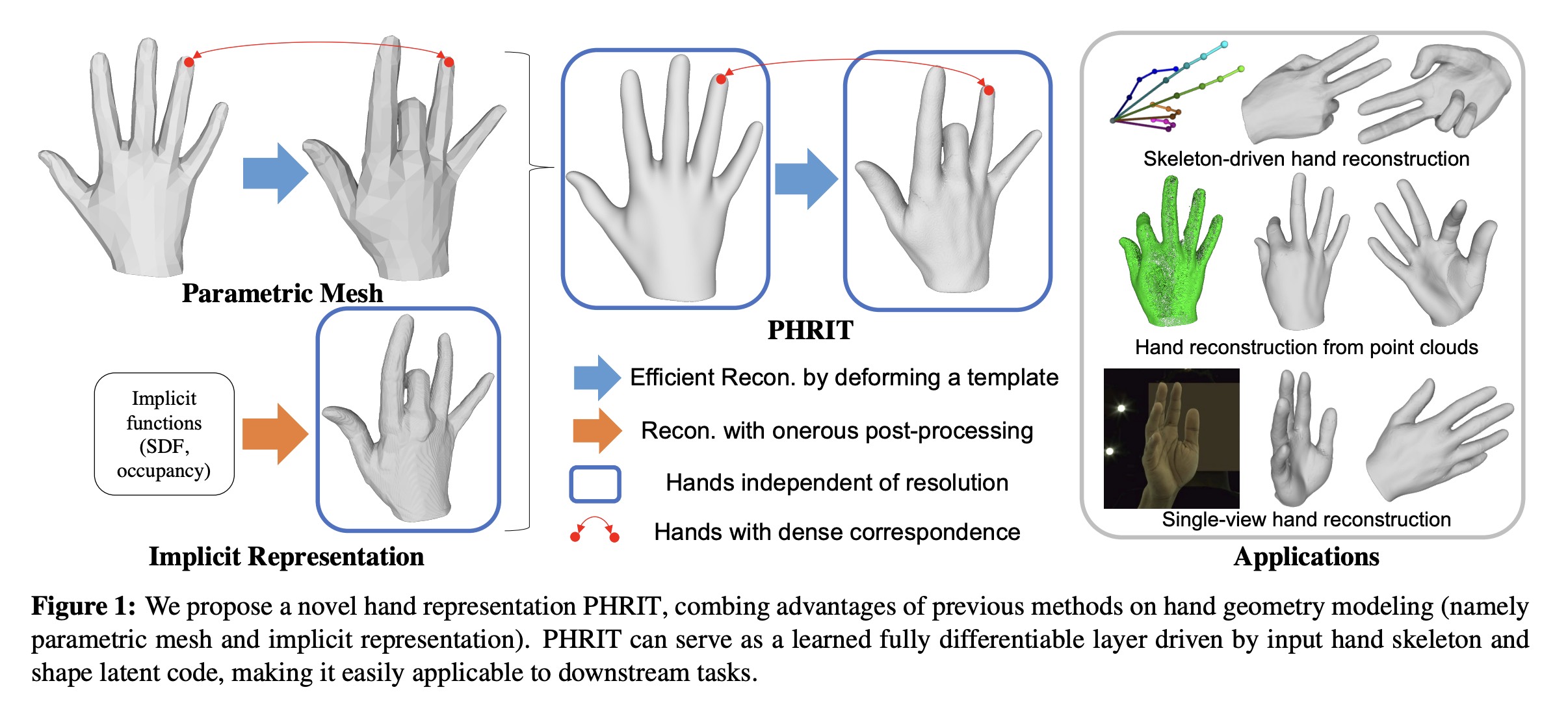
PHRIT: Parametric Hand Representation with Implicit Template
IEEE/CVF International Conference on Computer Vision (ICCV), 2023 PaperAbstractWe propose PHRIT, a novel approach for parametric hand mesh modeling with an implicit template that combines the advantages of both parametric meshes and implicit representations. Our method represents deformable hand shapes using signed distance fields (SDFs) with part-based shape priors, utilizing a deformation field to execute the deformation. |
|
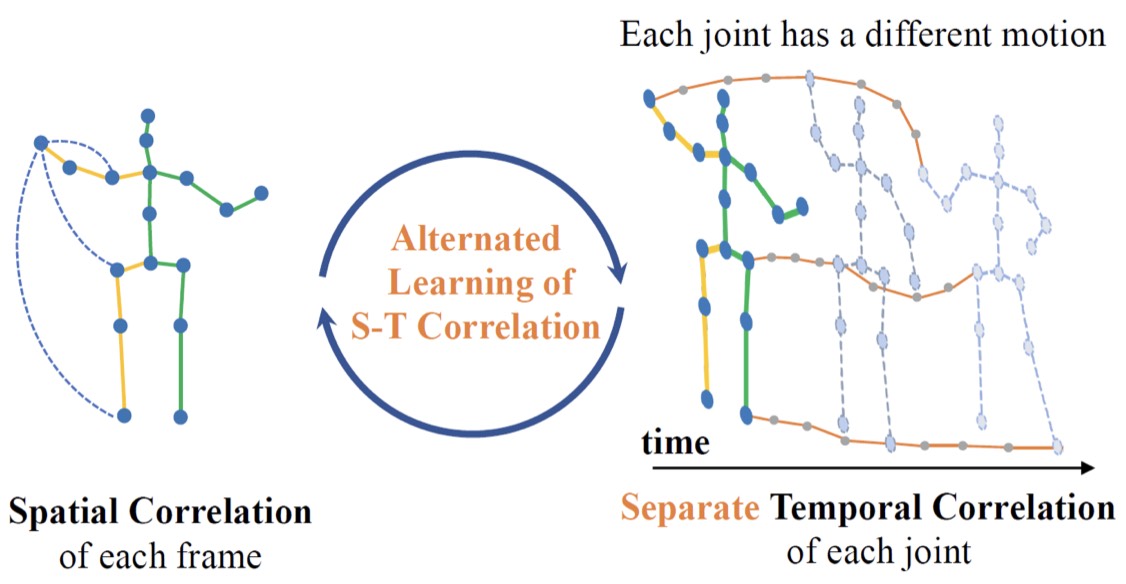
MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 Paper/ Video/ Code/ BibtexAbstractWe propose MixSTE (Mixed Spatio-Temporal Encoder), which has a temporal transformer to separately model the temporal motion of each joint and a spatial transformer to learn inter-joint spatial correlation. |
|
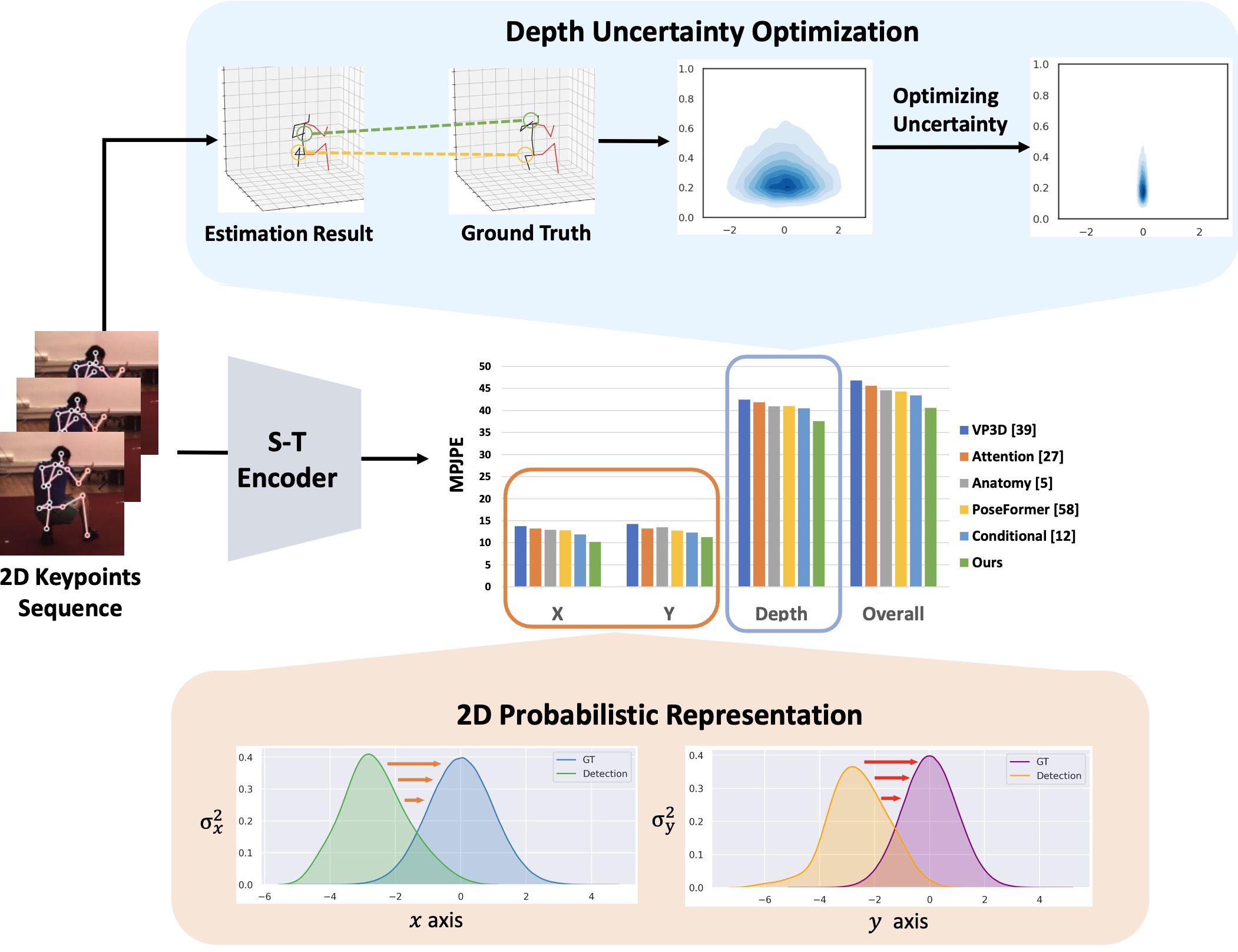
Uncertainty-Aware 3D Human Pose Estimation from Monocular Video
ACM International Conference on Multimedia (ACM MM), 2022 PaperAbstractWe propose an uncertainty-aware method to quantify and optimize the depth and 2D detection input respectively. |
Experience |
|
| Research Intern at BigAI, working with Yixin Chen and Siyuan Huang. | Sep, 2023 - Feb, 2025 |
| Research Intern at Tencent, working with Wei Zhuo. | Jan, 2022 - Jan, 2023 |
| Cooperation Project of WHU & Tencent in real-time super-resolution. | Dec, 2021 - May, 2022 |
| Research Intern at Huawei (Suzhou). | Jul, 2019 - Oct, 2019 |
Services & Activities |
| Conference Reviewer: CVPR'22/23/25, ICCV'23/25, ECCV'24, ICML'24, NeurIPS'24. |
| Journal Reviewer of: TPAMI, TIP, TSCVT. |
Awards & Scholarships |
|
| National Scholarship of Wuhan University | Oct, 2022 |
| 1st Runner-up in ICCV2021 MMVRAC Challenge Track 2&3. [Link] | Sep, 2021 |
| Top 10 first-year graduate students scholarship of WHU LIESMARS. | Nov, 2020 |
Education |
|
|
Doctor of Computer Applied Technology
|
|
|
Master of Computer Applied Technology
|
|
|
Bachelor Degree of Computer Science and Technology
|
|
Thanks for the Jon Barron template. |